
AI for Enterprise: The Importance of Retrieval Augmented Generation (RAG)
Retrieval Augmented Generation (RAG) is a method that enhances the capabilities of LLMs by integrating them with a dynamic retrieval system. In this article, we will discuss what exactly is RAG, and how does it enhance the functionality of LLMs in real-world applications.

The emergence of Large Language Models (LLMs) and their integration into business operations has been a groundbreaking development, bringing a new level of capability to a variety of applications.
However, they face a significant challenge: they are essentially "frozen in time." Their knowledge is limited to a cutoff point – this means that responses are based on knowledge available up to that date, and they don't have access to developments or updates that occurred after.
This limitation can lead to a phenomenon known as "hallucination," where the models provide responses to queries based on outdated or incomplete information. This issue is particularly critical in applications where accuracy and up-to-date knowledge are important.
To address this, the concept of "Retrieval Augmented Generation" (RAG) has come into the spotlight.
But what exactly is RAG, and how does it enhance the functionality of LLMs in real-world applications? Let's delve into this approach.
What is Retrieval Augmented Generation (RAG) ?
Retrieval Augmented Generation (RAG) is a method that enhances the capabilities of LLMs by integrating them with a dynamic retrieval system.
This system continuously feeds the LLM with updated and relevant information from external data sources.
In practice, such a solution first retrieves knowledge through a separate search system using semantic embeddings and then gives it to the LLM to read in order to ground its reasoning. It can be seen as a pipeline between LLMs and your data.
In contrast to fine-tuning, semantic embeddings don’t involve to re-train a model. It entails creating an embedding or a vector database containing all the selected knowledge; such a vector database is then used to find relevant data to feed the LLM, as part of a query. It solves the limitation of the traditional keyword search by providing search capabilities based on the contextual meaning of a passage of text. For instance, consider the query: "Where can I see a giant panda?" A semantic search system would associate this query with "zoos" or "wildlife sanctuaries" because it understands the user's intent is likely about finding locations to view giant pandas. In contrast, a basic keyword search might produce results-focused solely on the words "giant" and "panda," potentially missing the broader context.
Why it is so important to implement a RAG system?
When using AI with propriatory data of enterprises, it is crucial that the LLM can access up-to-date continuous data to retrieve all the necessary information and context.
When you think about an AI copilot for your enterprise, you expect to engage with your AI copilot to receive swift answers to your queries, sidestepping the process of combing through extensive search results.
A viable remedy for this concern is the incorporation of a search system (RAG) that feeds LLMs with verifiable data to produce content at scale.
Instead of navigating vast and growing volumes of data manually, you can pose direct questions to an AI copilot and receive curated responses. Beyond mere information retrieval, these systems have the capacity for content generation (by leveraging LLM) based on the knowledge they interface with.
It presents the following advantages:
- Updated data: Knowledge remains constantly updated and pertinent, given that the LLM is consistently fed with a current search index during each query. Users have always access to the latest data (connected), which cannot be forgotten among the vast amount of parameters of LLMs,
- Verification: LLM outputs aren't always verified and reliable, occasionally producing answers influenced by incorrect data. A RAG solution can be designed, for verification purposes, to allow users to review the specific documents provided to the LLM, ensuring that its responses are based on factual information. The model sidesteps the issue of catastrophic forgetting, as it pulls the necessary knowledge in real-time instead of attempting to internalize all information,
- Permissions: the tool can be designed, so the LLM refrains from accessing any data outside a user's permissions,
- Multilingual and cross-lingual: Compared to traditional keyword search, its ability goes beyond language barriers and can be used for global collaboration. Its searchability is not limited to one language in the query and the results. It can be set to perform cross-lingual searches (i.e., the query and the results are of a different language).
This solution represents a sophisticated evolution in data management and content generation for enterprises.
Additionally, RAG presents an economically efficient approach. It alleviates the need for the substantial computational and monetary investments required for training models or fine-tuning pre-existing ones.
How is it working?
To help you understand the technology and processes behind this technology, we will present you with a summary of each step.
- Data collection and cleaning: The first step is of course acquiring data from your relevant sources. A good practice is to clean and curate your dataset by removing any unnecessary artifacts.
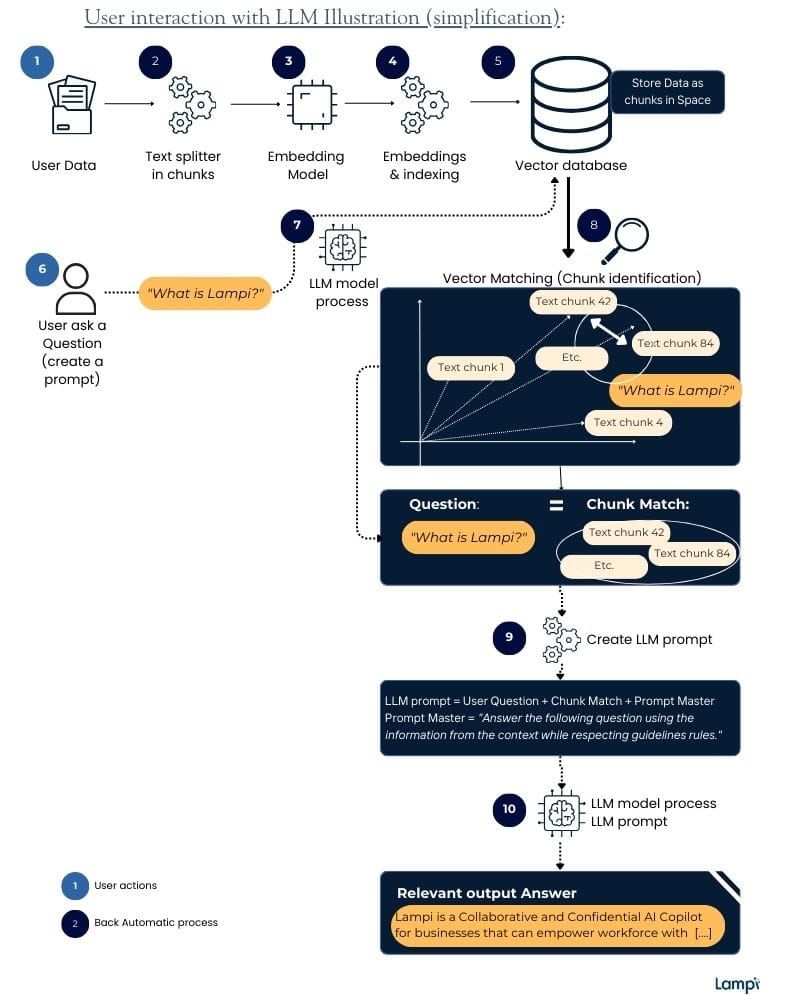
- Chunking: the RAG process starts with text extraction from your knowledge. All textual content is directly extracted for further steps. This information is subsequently partitioned into smaller segments, called 'chunks', with a predetermined character count (e.g., 200 or 1,000), ensuring the text is primed for deeper analysis. The length of your ‘chunk’ varies, but is generally comparable to the length of input and response you are using.
- Embedding: The process known as 'embedding' follows, generating multiple numerical representations or 'embeddings' for each text chunk that LLMs can understand. Embeddings are a way of representing data – almost any kind of data, like text, images, videos, users, music, whatever – as points in space where the locations of those points in space are semantically meaningful. In other words, text embeddings capture the context and meaning of the text. A very important property of embeddings is that similar pieces of text get assigned to similar lists of numbers.
- Vector database: All embeddings are meticulously ‘stored’ in a 'vector database' ready for future search queries. Every individual text chunk undergoes a thorough analysis with identical descriptors, culminating in the formation of a 'vector.' This vector, a comprehensive array of numbers, serves as a distinctive identifier, much like a unique fingerprint for each text chunk.
- Prompt: When a user asks a question, it's also converted into a vector in a similar manner to the text chunks. This ensures that the question can be accurately compared to the existing database of chunk descriptors. The conversion allows the AI to perform an accurate 'semantic search' by comparing the vector of the asked question to the vectors of pre-existing text chunks. The system (when it is well-designed) identifies and retrieves text chunks that are most closely related to the asked question.
- LLM Generation: The retrieved text chunks are used as part of a prompt that guides the tool in crafting an answer to the question. The prompt essentially instructs the tool to provide an answer using the context derived from the related text chunks.
The following image provides an overview of how it's working:
If semantic search has emerged as one of the best ways to retrieve the most relevant knowledge for a given query (even among a ton of documents) by looking for similarity-matching methods, it still has some limits.
Limits
Solely relying on these methods isn't always flawless. Embeddings capture the semantic closeness of statements, but that doesn't always guarantee the accuracy or relevance of the responses in relation to a given query.
Some responses might be semantically close, yet not directly answer the query, or might even be entirely incorrect. Others might be true statements but do not address the specific timeframe or context of the query. The quality of the prompt can also highly impact the quality of the outputs.
RAG systems can still produce errors or "hallucinations" if not equipped with strong guardrails. This highlights the importance of implementing robust mechanisms to maintain the integrity and accuracy of the information provided.
To overcome these limitations and achieve exceptional outcomes, RAG systems require advanced techniques. This includes leveraging an augmented RAG infrastructure combined with an iterative process, which continuously learns and adapts to provide more accurate responses.
For complex queries and nuanced understanding, fine-tuning can be essential. In practice, embedding and fine-tuning can go hand in hand to get better results. Efficient LLM embedding lays the groundwork, ensuring that the model comprehends prompts accurately. Building upon this, fine-tuning adjusts the model to the task or with the comprehensive knowledge at hand, making its responses to prompts more precise and of superior quality.
To limit hallucinations, one effective method involves creating positive pairs of (query, response) that are correct and relevant, alongside multiple negative pairs where the response is either incorrect or not directly answering the query. During the model's training process, the model is taught to favor the positive pairs and penalize the negative ones. By emphasizing the distinction between correct and incorrect responses in this manner, the search model becomes more proficient in providing accurate and relevant answers to user queries.
Lampi has been designed to provide one of the most advanced RAG systems for enterprise. In addition, we provide the expertise to leverage and fine-tune state-of-the-art large language models (LLMs) with your enterprise or domain knowledge, ensuring to provide an AI solution that is always a step ahead of your competitors.
Our experts are always ready to guide you on your AI journey, helping you understand and navigate the complex world of AI.
Don't forget to follow us on Twitter, Instagram, and LinkedIn!