
Fine-Tuning LLMs for Unlocking Business Efficiency

Large Language Models (LLMs) have shown great promise as highly capable AI copilots that are incredible at generating coherent and contextually relevant text based on given prompts and can assist in a wide range of tasks.
The use of open-source models offers a golden path, especially for organizations that don't have the resources to build a model from scratch and are looking to implement a secure AI solution. Open-source LLMs are models whose architectures, pre-trained weights, and code are publicly available, allowing developers, researchers, and businesses to use, modify, and build upon them. Examples of open-source LLMs include OpenAI's GPT-2, Meta's Llama v2, and Google's BERT models.
However, while LLMs are indeed powerful and capable of remarkable feats, they often require a process known as 'fine-tuning' to achieve their maximum efficacy. Indeed, models are great generalists, but for enterprise use cases, they often fall short as specialists, particularly when there's a need for domain-specific or company-specific information.
Fine-tuning these models on your domain-specific data can provide the bespoke solutions your organization needs, without the astronomical costs usually associated with AI implementations.
In this blog post, we'll provide an overview of what is fine-tuning, and why you might need to fine-tune LLM in the context of your operations.
What is fine-tuning?
Fine-tuning a large language model refers to the process of adjusting and adapting a previously trained model to better handle certain tasks or specialize in a particular domain.
To be specific, foundational LLMs are initially trained on an extensive collection of varied textual data, giving them a grasp of general language patterns, grammar, and context. This helps the model grasp the intricacies of language and establishes a robust foundation for a general understanding.
However, this foundational knowledge doesn't necessarily tailor the model for expertise in specific tasks, it merely equips it with a wide-ranging understanding of language patterns. A lot of sectors deploy specialized terminology, industry-specific phrases, and technical lexicons that might not be prominently present in a universal language model's foundational training data. Adapting the model with industry-centric datasets equips it to recognize and produce precise feedback tailored to the company's sectoral context.
Through fine-tuning, LLMs can also be optimized to perform better in a specific task by learning from examples for that domain.
For example, Bloomberg has developed BloombergGPT, a large-scale language model tailored for the financial industry. This model focuses on financial natural language processing tasks such as sentiment analysis, named entity recognition, and news classification.
Smaller LLMs that have been fine-tuned on a specific use case often outperform larger ones that were trained more generally. For example, Google's Med-PaLM2 is a language model fine-tuned on a curated corpus of medical information and Q&As. Med-PaLM2 is 10 times smaller than GPT-4 but performs better on medical exams.
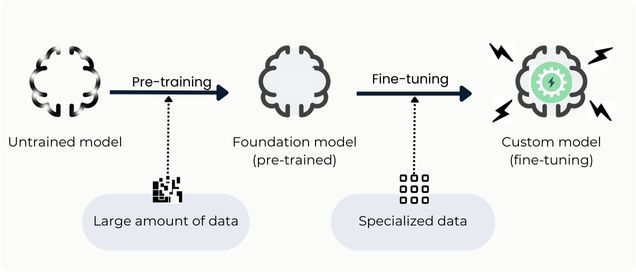
The necessity for fine-tuning stems from the unique characteristics and requirements inherent to every specific application or task.
For example, a fine-tuned LLM could be trained on:
- Financial lexicons or mathematical formulas to help in financial analyses,
- A set of HR interviews and employee feedback to refine recruitment processes and enhance employee satisfaction,
- A record of customer service interactions to automate and improve client support,
- A dataset of competitor intelligence to inform business strategy and anticipate market shifts,
- A collection of financial transactions to detect fraud and unusual patterns,
- A catalog of business contracts to assist in contract review, ensuring compliance and identifying potential risks; or
- directly with company data.
Why train your own LLM?
There are plenty of reasons why a company might decide to train its own LLMs, ranging from data privacy and security to increased control over updates and improvements.
To illustrate, consider a financial chatbot developed to assist financial analysts in predicting stock market movements. The objective of this chatbot is to analyze past market data, integrate real-time financial news, and offer projections for potential market shifts or advice on investment strategies. To construct an effective financial chatbot, an LLM needs fine-tuning to ensure its accuracy and reliability in the highly nuanced domain of finance. Here are the advantages of fine-tuning in this scenario:
Domain-specific Knowledge: The financial sector has its distinct terminology and conventions. Fully understanding the intricate financial jargon vital for precise market predictions necessitates fine-tuning.
Contextual understanding: Fine-tuning the LLM with historical market data and contemporary financial literature enables it to better contextualize market trends and make more informed predictions.
Bias Reduction: Training the LLM on a diverse and representative financial dataset helps in mitigating biases, ensuring fair and impartial financial recommendations.
More generally, fine-tuning a model allows for better control over the model's behavior and output. By training the model on a specific dataset, you can guide the model to generate responses that are more relevant and appropriate for the task at hand.
In addition, one of the main reasons is that open-source LLM is a perfect solution to leverage LLMs without disclosing data by storing them on-premises or on a dedicated server.
How to fine-tune a model?
Most large enterprises are expected to build or optimize one or more GenAI models specific to their business requirements within the next few years.
However, fine-tuning a large language model is a meticulous process that involves multiple stages of selection, training, and optimization. Each step is essential to ensure that the model performs at its best for the specific application of a company, especially when tailoring it to specific tasks or industries.
Such a process involves notably:
Targeting models: Identifying the large pre-trained models that are best suited for your needs. While choosing the base model, you should consider whether the model fits your specific task, input and output size of the model, your dataset size, and whether the technical infrastructure is suitable for the computing power required for fine tuning.
Assessing the models: Examine the models to get a sense of their strengths, weaknesses, and general capabilities. This step ensures that the models you're considering align with your specific requirements and constraints.
Comparison: After your audit, compare the models to determine which one best fits your needs. This could be based on their performance metrics, computational efficiency, or any domain-specific requirements you might have. Consider a variety of trade-offs between model size, context window, inference time, memory footprint, and more.
Selection of data: Once you have chosen a model to fine-tune, you will need to gather the data on which you will perform the fine-tuning. This may include data cleaning, text normalization, and converting the data into a format that is compatible with the LLM’s input requirements (i.e. data labeling). This data should be representative of the task you want the model to perform or the expertise you want the model to master, and should be of high quality.
Fine-tuning configuration and data training: You need to select the appropriate model architecture, learning rate, batch size, and other parameters.
With your selected data, start the training process. This involves exposing the model to your data, allowing it to adjust its parameters and thereby "learn" from your specific dataset. The fine-tuning process may involve several rounds of training on the training set, validation on the validation set, and hyperparameter tuning to optimize the model’s performance.
Over the years, researchers developed several techniques to fine-tune models with high modeling performance while only requiring the training of only a small number of parameters. These methods are usually referred to as parameter-efficient finetuning techniques (PEFT), which are different from a full parameter fine-tuning method that fine-tunes all the parameters of all the layers of the pre-trained model. Full parameter fine-tuning can achieve the best performance but it is also the most resource-intensive and time-consuming.
Instead of fine-tuning the model’s billions of parameters, we can leverage PEFT instead, Parameter-Efficient Fine-Tuning. As the name implies, it is a subfield that focuses on efficiently fine-tuning an LLM with as few parameters as possible. There are two important PEFT methods: LoRA (Low Rank Adaptation) and QLoRA (Quantized LoRA), which are not detailed in this article.
Deploying the model: Once you’ve trained and evaluated your model, it's time to deploy it into production. Infrastructure needs to be highly considered ensuring that your model runs efficiently and responsively.
Feedback and iteration: Once you’ve deployed your model, gather feedback, and then iterate rapidly based on that feedback. It's also important for our process to remain robust to any changes in the underlying data sources, model training objectives, or server architecture. This allows us to take advantage of new advancements and capabilities in a rapidly moving field where every day seems to bring new and exciting announcements.
Conclusion
As we've explored throughout this article, the realm of open-source models coupled with fine-tuning offers an enticing avenue for organizations looking to integrate GenAI into their operations. It provides a balanced approach that combines customization and affordability, enabling businesses to achieve highly specific AI solutions without breaking the bank.
However, to fully unleash the potential of fine-tuned open-source models, there's another crucial element to consider—semantic embeddings. While fine-tuning helps tailor the model to your unique dataset and business objectives, semantic embeddings can further enrich the model's understanding of your up-to-date and specific context, resulting in even more accurate and insightful outputs.
In practice, combining fine-tuned open-source models with semantic embeddings often proves to be a game-changer, fine-tuning the machine's abilities to understand and generate content that is not just relevant but also deeply insightful.
So, what exactly are semantic embeddings and how can they be employed alongside fine-tuned open-source models to create a next-level AI solution for your organization? We'll delve into this subject in our next article, providing you with a comprehensive guide to mastering this advanced yet incredibly rewarding technique.
At Lampi, we provide the expertise to leverage and fine-tune state-of-the-art large language models (LLMs) with your enterprise or domain knowledge, ensuring they outperform standard models like ChatGPT.
Our experts are always ready to guide you on your AI journey, helping you understand and navigate the complex world of AI.
So, why wait? Step into the future with Lampi and embark on your AI journey today!
Don't forget to follow us on Twitter, Instagram, and LinkedIn!